

ChatGPT and Artificial Intelligence
Today, any discussion of artificial intelligence is bound to include ChatGPT, the ubiquitous chatbot built on the GPT of OpenAI Large Language Models (LLM). But how can you meet the demands of this generative AI technology in your data center?
The chatbot was launched at the end of the year 2022 and is making waves with its content generation capabilities. People use ChatGPT and bots from other competitors GPT to get answers to complex questions and automate tasks like writing software code and producing marketing copy.
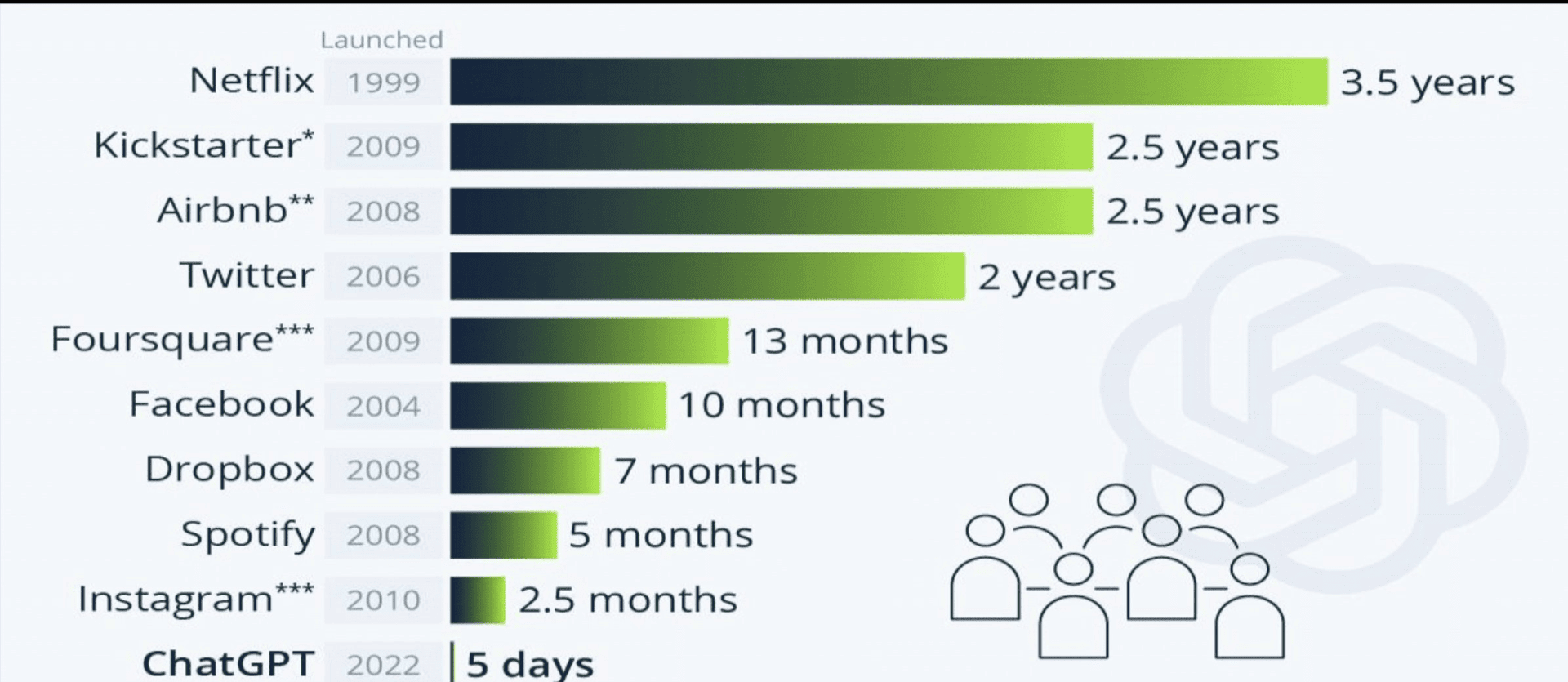
According to Statista, data and trends portal. It took only 5 days to ChatGPT reach one million users. Something that other giant companies like Netflix, Airbnb or Spotify struggled to reach rapidly.
But with all the possibilities inherent to this technology of Generative AI, it has been difficult to use fundamental models to their full potential. Most models out there have been trained on publicly available data, making them less than ideal for specific business applications, such as querying sensitive internal documents.
Building large language models: a costly affair within data centers
The task of creating a Large Language Model or LLM, such as GPT-3 or GPT-4, requires several steps, starting with compute-intensive training that requires hundreds, if not thousands, of expensive GPUs clustered on data center servers over several weeks or months.
Datacenters must have certifications to be able to host advanced computing systems, such as certification Tier III of the Uptime Institute or greater. Today, DataTrust It is the only TIER III commercial data center for El Salvador.

«Initial training requires a very significant amount of computing power. For example, the model BLOOM, a 176 billion parameter open source alternative to GPT-3, required 117 days of training on a cluster of 384 GPUs. This is roughly equivalent to 120 years of GPU,” – Julien Simon of Hugging Face during a Venturebeat interview

According Julien Simon of Hugging Face, as the size of the model increases, the amount of GPU necessary to train and retrain it.
Google, for example, had to connect 6,144 chips to train its model PaLM of 540 billion parameters. The process also requires expertise in advanced training techniques and tools (such as Microsoft DeepSpeed and Nvidia MegaTron-LM), which may not be readily available in the organization.

After training is complete, these chips are required to perform inference on the model continuously, further increasing the cost. To put it in perspective, using just 500 Nvidia DGX A100 multi-GPU servers, which are commonly used for training and inference LLM, at $199,000 each would mean spending around $100 million on the project.
In addition to this, the additional power consumption and thermal output coming from the servers will increase the total cost of ownership.
This is a big investment in data center infrastructure, especially for companies that are not AI organizations and are just looking to LLM to accelerate certain business use cases.
Bloomberg GPT: The ideal approach to a certified data center for the AI era
Unless a company has unique, high-quality data sets that can create a model with a strong competitive advantage that is worth the investment, the best way forward is to adjust the LLM existing open source solutions for specific use cases for the organization’s own data, such as corporate documents, customer emails, etc.
A good counterexample is the model BloombergGPT, a 50 billion parameter model trained by Bloomberg from scratch.
Bloomber GPT is crowned as one of the first machine learning languages oriented to Finance
Tuning, on the other hand, is a much lighter process that will require only a fraction of the time, budget and effort. The Hugging Face center is an Artificial Intelligence (AI) firm that reached a market value of 4.5 billion dollars, in whose investment Google, Amazon, Nvidia, Salesforce, AMD, Intel, IBM y Qualcomm.
“Initially, we relied on a cloud-hosted MLOps infrastructure, which allowed us to focus on developing our technology rather than managing hardware,” said Bars Juhasz, CTO and co-founder of content generator Undetectable AI. “As we’ve grown and our solution architecture has matured beyond the early stages of rapid R&D, it now makes sense to explore local model hosting.”
Cloud platforms like AWS, Google Cloud, or DataTrust Cloud continue to offer expanded training options, now supporting not only NVIDIA GPUs but also those from AMD and Intel.
However, in scenarios where local laws or regulations restrict cloud usage, the default choice becomes on-premises deployment using accelerated hardware such as GPUs.